

 光环助手2025v5.38.8官方最新版手机工具立即下载
光环助手2025v5.38.8官方最新版手机工具立即下载 微店输入法v1.4.0 安卓版手机工具立即下载
微店输入法v1.4.0 安卓版手机工具立即下载 vivo应用商店v9.13.20.0官方最新版手机工具立即下载
vivo应用商店v9.13.20.0官方最新版手机工具立即下载 Freeme OS轻系统V3.1.0官方免费版手机工具立即下载
Freeme OS轻系统V3.1.0官方免费版手机工具立即下载 爱吾游戏宝盒安卓版V2.4.0.1手机工具立即下载
爱吾游戏宝盒安卓版V2.4.0.1手机工具立即下载 kingroot一键root工具v3.0.1.1109 最新pc版手机工具立即下载
kingroot一键root工具v3.0.1.1109 最新pc版手机工具立即下载 云电脑appv5.9.9.1官方版手机工具立即下载
云电脑appv5.9.9.1官方版手机工具立即下载 壁虎数据恢复安卓版V2.5.6官方版手机工具立即下载
壁虎数据恢复安卓版V2.5.6官方版手机工具立即下载 天天酷跑v1.0.126.0安卓版
天天酷跑v1.0.126.0安卓版
 sky光遇北觅全物品解锁版v0.28.5(313329)最新版
sky光遇北觅全物品解锁版v0.28.5(313329)最新版
 天天爱消除2024最新版v2.37.0.0Build32
天天爱消除2024最新版v2.37.0.0Build32
 原神手游v5.4.0_30057195_30231699最新版
原神手游v5.4.0_30057195_30231699最新版
 可口的咖啡美味的咖啡无限钞票免广告版v0.1.4最新版
可口的咖啡美味的咖啡无限钞票免广告版v0.1.4最新版
 王者荣耀国际版honor of kings官方最新版v10.20.3.1安卓版
王者荣耀国际版honor of kings官方最新版v10.20.3.1安卓版
 手机京东appv15.0.60安卓版
手机京东appv15.0.60安卓版
 UC浏览器安卓版v17.4.2.1373官方最新版
UC浏览器安卓版v17.4.2.1373官方最新版
 酷我音乐盒2022最新安卓版V11.1.6.2官方版
酷我音乐盒2022最新安卓版V11.1.6.2官方版
 MOMO陌陌2022最新版本V9.15.10官方版
MOMO陌陌2022最新版本V9.15.10官方版
 全民k歌2022年最新版V9.5.38.278 官方版
全民k歌2022年最新版V9.5.38.278 官方版
 小红书app2024最新版v8.72.0安卓版
小红书app2024最新版v8.72.0安卓版
DeepSeek华为版最新版本是杭州深度求索官方推出的AI助手,其总参数超过600B的DeepSeek-V3大模型一经开源即在海内外引起震动。这款AI助手具有多项性能指标,可与海外顶尖模型相媲美,以其更快的速度和更强大全面的功能,为用户答疑解惑,助力高效美好的生活。
官方说明
DeepSeek 官方推出的 AI 助手,免费体验与全球领先 AI 模型的互动交流。
使用一经开源即在海内外引起震动、总参数超过 600B 的 DeepSeek-V3 大模型,多项性能指标对齐海外顶尖模型,用更快的速度、更加全面强大的功能为你答疑解惑,助力高效美好的生活。
软件特色
智能对话
高智商模型,顺滑对话体验
深度思考
先思考后回答,解决推理难题
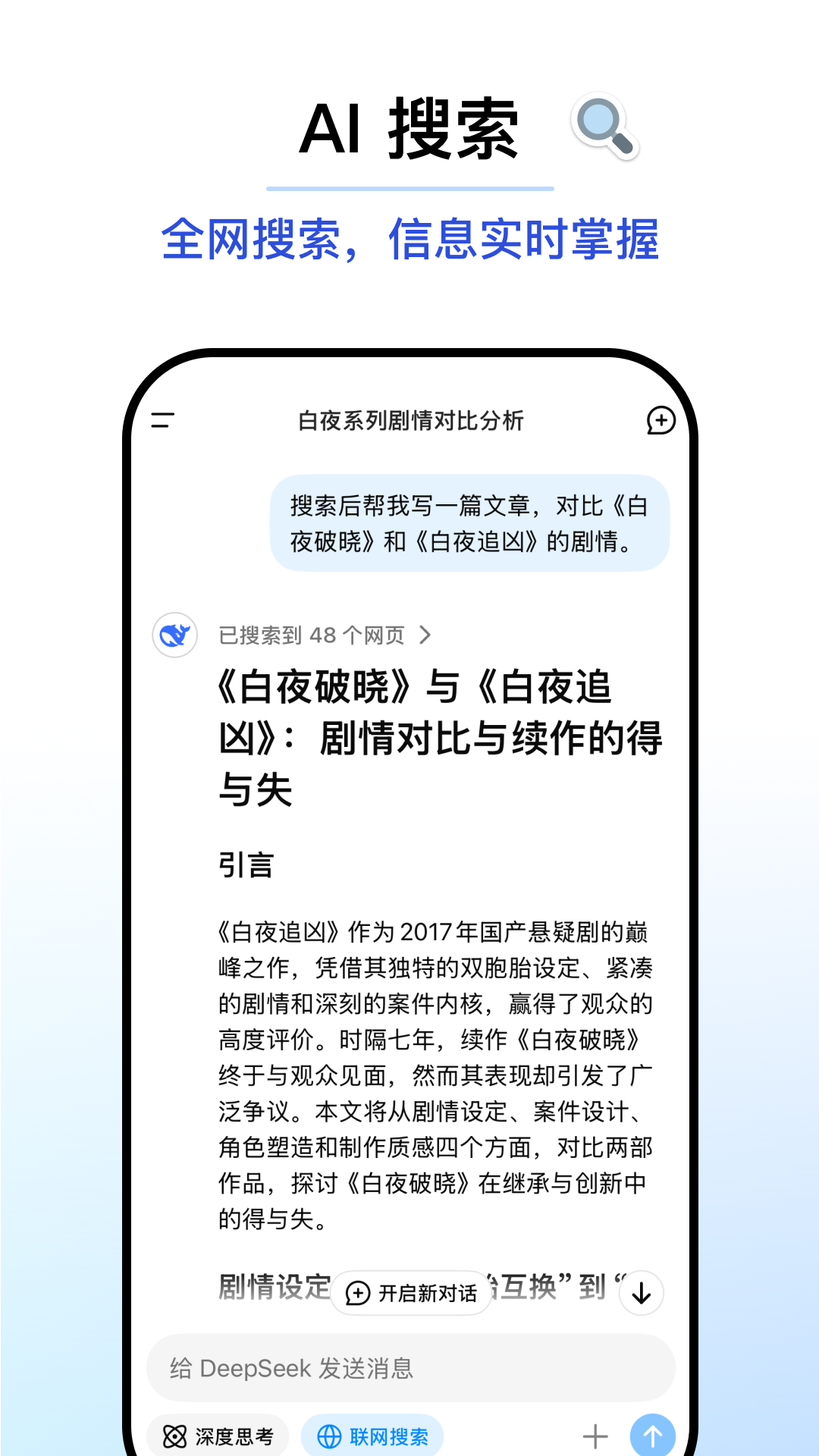
AI 搜索
全网搜索,信息实时掌握
文件上传
阅读长文档,高效提取信息
DeepSeek V3模型驱动
App背后的模型正是前段时间爆火的DeepSeek V3――以1/11算力训练超越Llama 3的模型,震撼一整个AI圈。
它是一个参数量为671B的MoE模型,激活37B,在14.8T高质量token上进行了预训练。
它发布即完全开源,在多项测评上,DeepSeek V3达到了开源SOTA,超越Llama 3.1 405B,能和GPT-4o、Claude 3.5 Sonnet等TOP模型正面掰掰手腕。
而其价格比Claude 3.5 Haiku还便宜,仅为Claude 3.5 Sonnet的9%。
而如果要平衡性能和成本,它成了DeepSeek官方绘图中唯一闯进“最佳性价比”三角区的模型。
也正因为之前DeepSeek太受关注,还有一些假冒App,网友们深受其害。
现在总算是有了官方正版可以使用啦~
deepseek和豆包哪个厉害
DeepSeek:专业数据分析与知识挖掘助手
DeepSeek定位为专业场景下的数据分析和知识挖掘工具,专为技术与商业领域设计。
特点与优势:
强大的数据处理和技术文档解析能力。提供深入的知识图谱和报告生成功能。支持多领域的专业知识问答。
适用场景:
适合科研人员、企业决策者和需要深度分析的用户。?
豆包:轻松有趣的社交型助手
豆包定位为一款注重互动性和趣味性的AI助手,非常适合日常聊天和娱乐应用。
特点与优势:
响应快速,语言风格轻松幽默。擅长趣味问答、闲聊和简单信息查询。适合需要轻松交流或快速生成娱乐内容的用户。
适用场景:
适合日常生活中的娱乐需求,如调节心情或进行简单的知识探索。
总体来说,DeepSeek和豆包各有特色,因此,选择哪个更厉害取决于具体的应用场景和需求。
使用说明
百科知识:DeepSeek-V3 在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代 DeepSeek-V2.5 显著提升,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。
代码:DeepSeek-V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非 o1 类模型,并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
长文本:长文本测评方面,在DROP、FRAMES 和 LongBench v2 上,DeepSeek-V3 平均表现超越其他模型。
数学:在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3 大幅超过了所有开源闭源模型。
中文能力:DeepSeek-V3 与 Qwen2.5-72B 在教育类测评 C-Eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。
关于我们
DeepSeek Chat:支持自然语言处理、问答系统、智能对话、智能推荐、智能写作和智能客服等多种任务。能够理解并回应用户的各种问题和需求,包括闲聊、知识查询、任务处理等。提供多语言支持,能够根据用户的语气和情绪调整对话风格。支持文件上传功能,可扫描读取图片或文件中的文字内容。
DeepSeek Coder:专注于编程代码生成、调试和优化。在编程能力上显著提升,能够提供多个解决方案以解决编程瓶颈问题。支持代码优化和重构任务,提高代码可读性和可维护性。模型训练成本低,支持大规模数据处理。
DeepSeek R1:支持模型蒸馏,蒸馏出的1.5B、7B、8B、14B等小模型非常适合在本地部署,尤其适合资源有限的中小企业和开发者。基于强化学习(RL)驱动,专注于数学和代码推理,支持长链推理(CoT),适用于复杂逻辑任务。
DeepSeek-R1 发布,性能对标 OpenAI o1 正式版
DeepSeek V3:参数量为671亿,激活参数为37亿。在14.8T高质量token上进行了预训练,性能表现达到开源SOTA水平,超越Llama 3.1 405B和GPT-4o等顶尖模型,在数学能力方面表现尤为突出。训练成本仅需约558万美元,相比传统模型大幅降低。完全开源,训练细节公开。
DeepSeek V2:参数量为236亿,激活参数为21亿。支持128K上下文窗口,显存消耗低,每token成本大幅降低。
性能对齐 OpenAI-o1 正式版
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
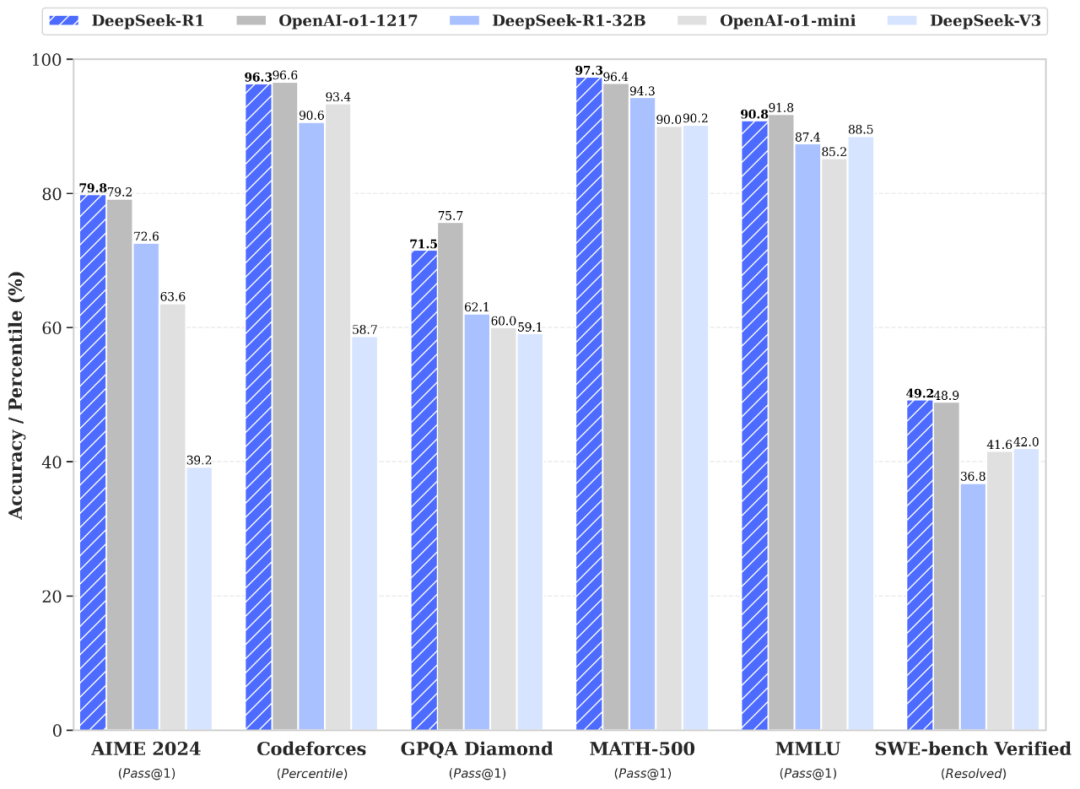
蒸馏小模型超越 OpenAI o1-mini
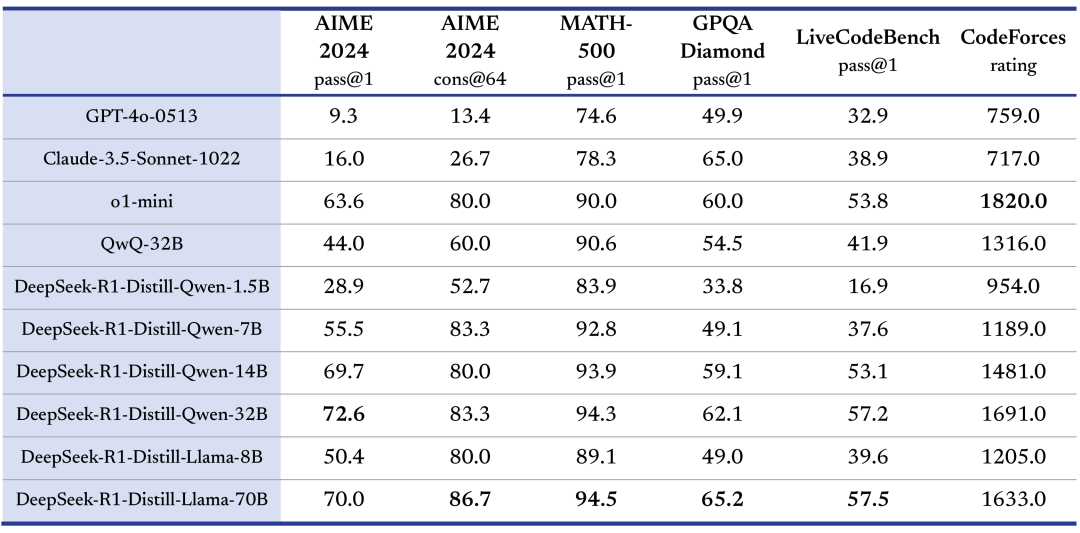
我们在开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
开放的许可证和用户协议
为了推动和鼓励开源社区以及行业生态的发展,在发布并开源 R1 的同时,我们同步在协议授权层面也进行了如下调整:
模型开源 License 统一使用 MIT。我们曾针对大模型开源的特点,参考当前行业的通行实践,特别引入 DeepSeek License 为开源社区提供授权,但实践表明非标准的开源 License 可能反而增加了开发者的理解成本。为此,此次我们的开源仓库(包括模型权重)统一采用标准化、宽松的 MIT License,完全开源,不限制商用,无需申请。
产品协议明确可“模型蒸馏”。为了进一步促进技术的开源和共享,我们决定支持用户进行“模型蒸馏”。我们已更新线上产品的用户协议,明确允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。
DeepSeek App与网页端
登录DeepSeek官网或官方App,打开“深度思考”模式,即可调用最新版 DeepSeek-R1 完成各类推理任务。
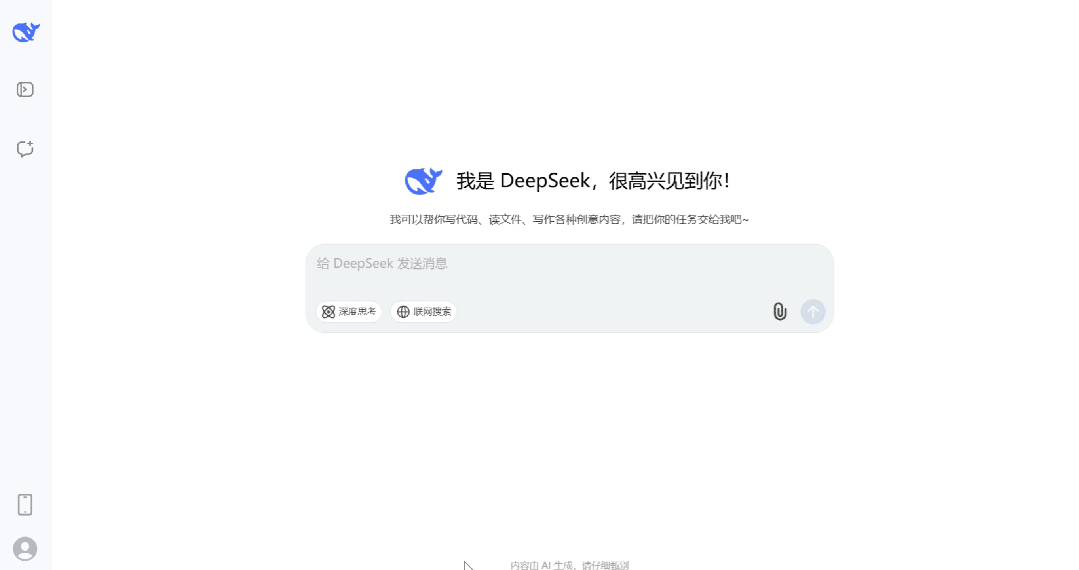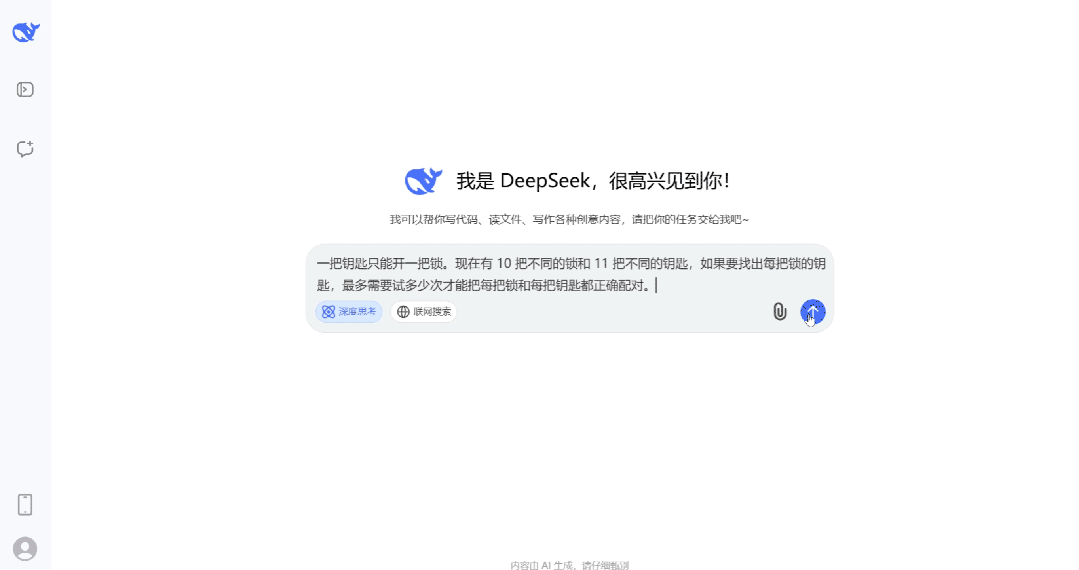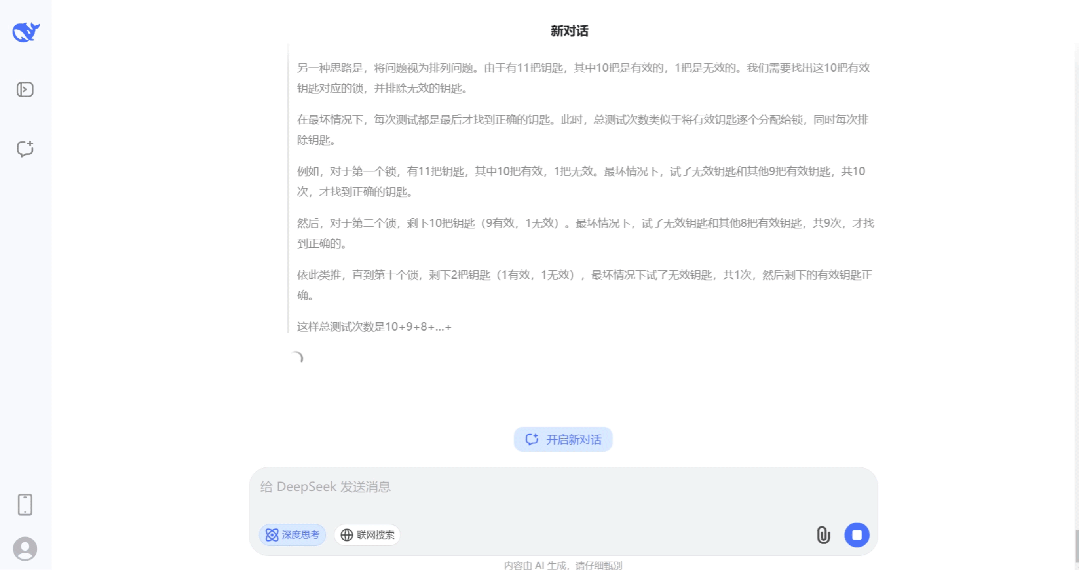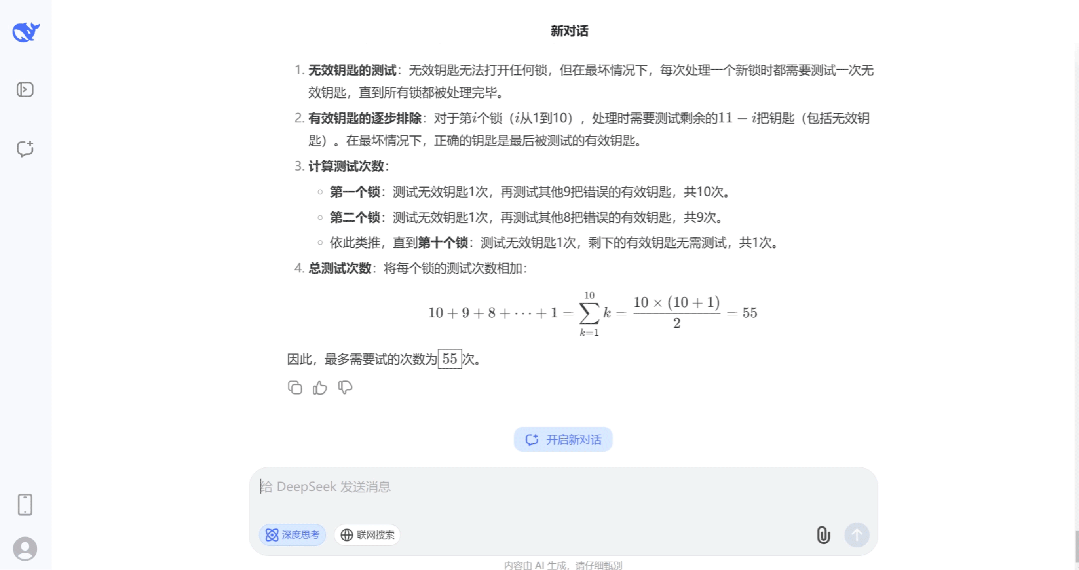
- 安卓版
- PC版
- IOS版



 逐光剧场红包版app1.0.1最新版立即下载
逐光剧场红包版app1.0.1最新版立即下载 PMX Pro权限管理高级版下载最新版v1.27-pro立即下载
PMX Pro权限管理高级版下载最新版v1.27-pro立即下载 同城寻秘app安卓版1.1.0最新版立即下载
同城寻秘app安卓版1.1.0最新版立即下载 picwish佐糖appv2.0.4立即下载
picwish佐糖appv2.0.4立即下载 zero Vectras VM数据包下载汉化版zero-v3.0-cn立即下载
zero Vectras VM数据包下载汉化版zero-v3.0-cn立即下载 happyshort短剧app最新版1.4.9官方版立即下载
happyshort短剧app最新版1.4.9官方版立即下载 汉水襄阳新闻客户端v1.3.5安卓版立即下载
汉水襄阳新闻客户端v1.3.5安卓版立即下载 DJI Ronin app安卓版v1.9.0官方版立即下载
DJI Ronin app安卓版v1.9.0官方版立即下载 白鸽社区app官方正版v5.24安卓版立即下载
白鸽社区app官方正版v5.24安卓版立即下载 欧易钱包官方app全新版v6.110.0官方版立即下载
欧易钱包官方app全新版v6.110.0官方版立即下载 欧易app官方下载2025最新版v6.110.0官方版立即下载
欧易app官方下载2025最新版v6.110.0官方版立即下载 月鼠小说解锁会员v4.7.1.1立即下载
月鼠小说解锁会员v4.7.1.1立即下载 疯狂刷题app官方正版v1.16.22最新版立即下载
疯狂刷题app官方正版v1.16.22最新版立即下载 飞蓝电视app官方下载最新版本V1.0.1立即下载
飞蓝电视app官方下载最新版本V1.0.1立即下载 万能工具箱app免费下载官方安卓版1.2.6立即下载
万能工具箱app免费下载官方安卓版1.2.6立即下载 月影剧场app官方正版1.0.1安卓版立即下载
月影剧场app官方正版1.0.1安卓版立即下载 米读书城官方下载解锁高级版v2.43.1.0213.1200安卓立即下载
米读书城官方下载解锁高级版v2.43.1.0213.1200安卓立即下载 爱给网官方免费下载素材1.0.1立即下载
爱给网官方免费下载素材1.0.1立即下载 deepseek YYDS官方下载最新版
deepseek YYDS官方下载最新版 Deepseek硅基流动手机版
Deepseek硅基流动手机版 DeepSeek API文档官方提示库
DeepSeek API文档官方提示库 DeepSeek官方提示库官方版
DeepSeek官方提示库官方版 DeepSeek谷歌版下载2025官方最新版
DeepSeek谷歌版下载2025官方最新版 deepseek海外版下载2025最新版
deepseek海外版下载2025最新版 小肾魔盒app
小肾魔盒app 人工智能app免费下载
人工智能app免费下载 deepseek训练模型下载
deepseek训练模型下载 我在aiapp下载2025官方最新版
立即下载
手机工具
我在aiapp下载2025官方最新版
立即下载
手机工具
 鸡乐盒v5.0版本
立即下载
手机工具
鸡乐盒v5.0版本
立即下载
手机工具
 旋风免费加速器app安卓版
立即下载
手机工具
旋风免费加速器app安卓版
立即下载
手机工具
 scene工具箱软件安卓官方最新版本
立即下载
手机工具
scene工具箱软件安卓官方最新版本
立即下载
手机工具
 鸡乐盒7.0无广告最新版
立即下载
手机工具
鸡乐盒7.0无广告最新版
立即下载
手机工具
 TapTap
立即下载
手机工具
TapTap
立即下载
手机工具
 迅雷av下载2024官方版
立即下载
手机工具
迅雷av下载2024官方版
立即下载
手机工具
 鸡乐盒8.0无广告悬浮窗
立即下载
手机工具
鸡乐盒8.0无广告悬浮窗
立即下载
手机工具
 viggle ai下载安卓版
立即下载
手机工具
viggle ai下载安卓版
立即下载
手机工具
 momo检测环境异常软件
立即下载
手机工具
momo检测环境异常软件
立即下载
手机工具
热门评论
最新评论